
Background Knowledge:
Compression is one of the key outcomes of information theory, which should be studied by every single engineer regardless the area of engineering they are in. Without compression we create systems which use unnecessary data.
Quick Run:
Compression has many different subfields in it, I will only talk about a few that I have become aqquinted with.
Huffman Encoding:

This is one of the simplest compression schemes. Unfortunately, this is poor for dynamically changing sources of information. Areas where it is impossible to predict EMG data. These trees are built bottom up, which means the data is all generated first.
Arithmetic Coding:
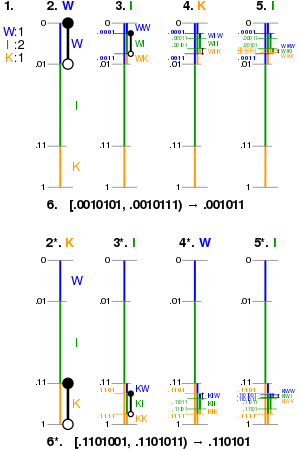
Arithmetic is likely one of the fastest dynamic source compression techniques I know of. There are plenty of additions in here to ensure it is faster, we can do this using kernels and pipelines.
LZ Family Coding:
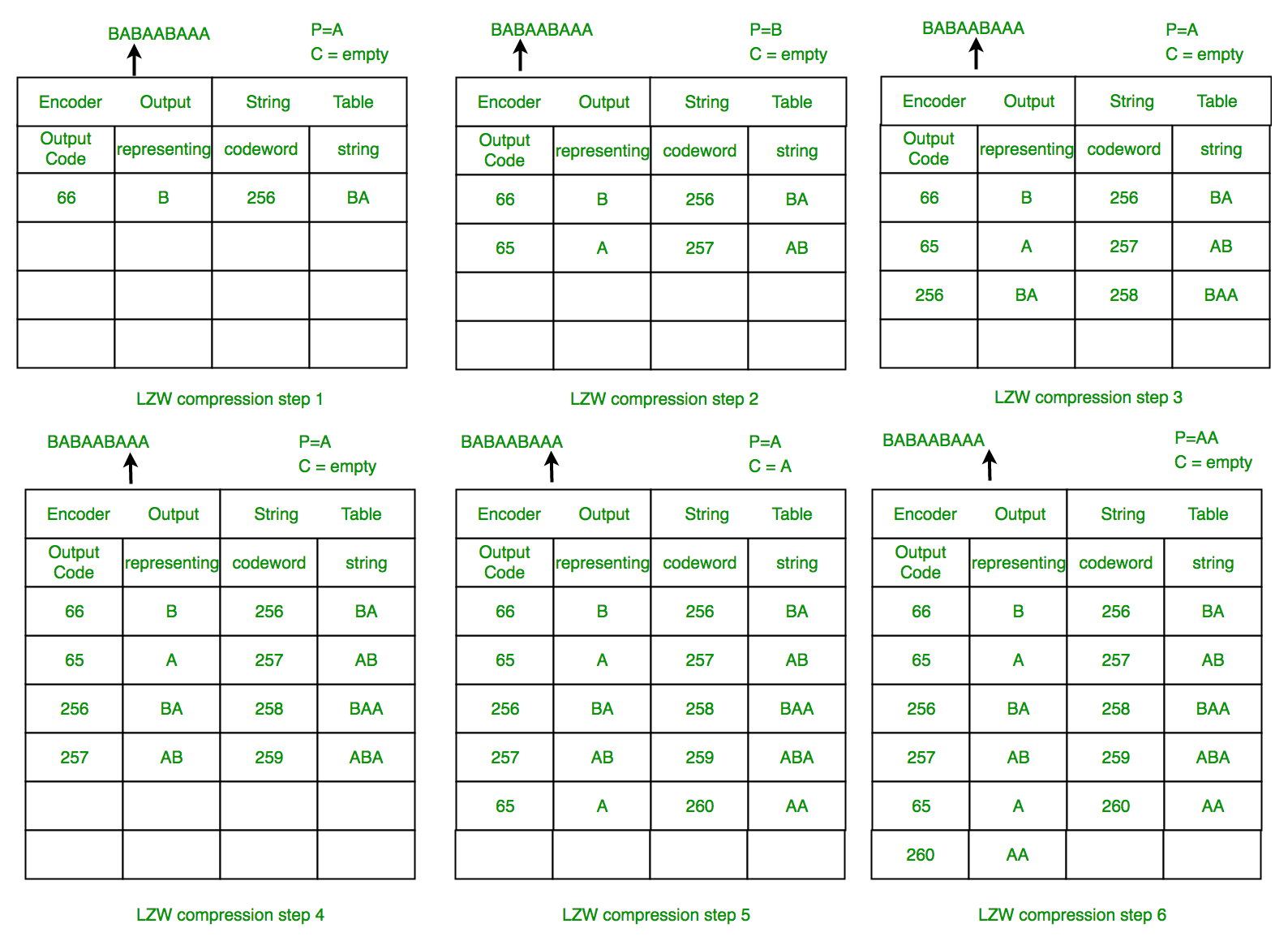
While not as fast as Arithmetic Encoding, this family has a lot of benefits when it comes to generating minimal outputs.
Nevill-Manning:
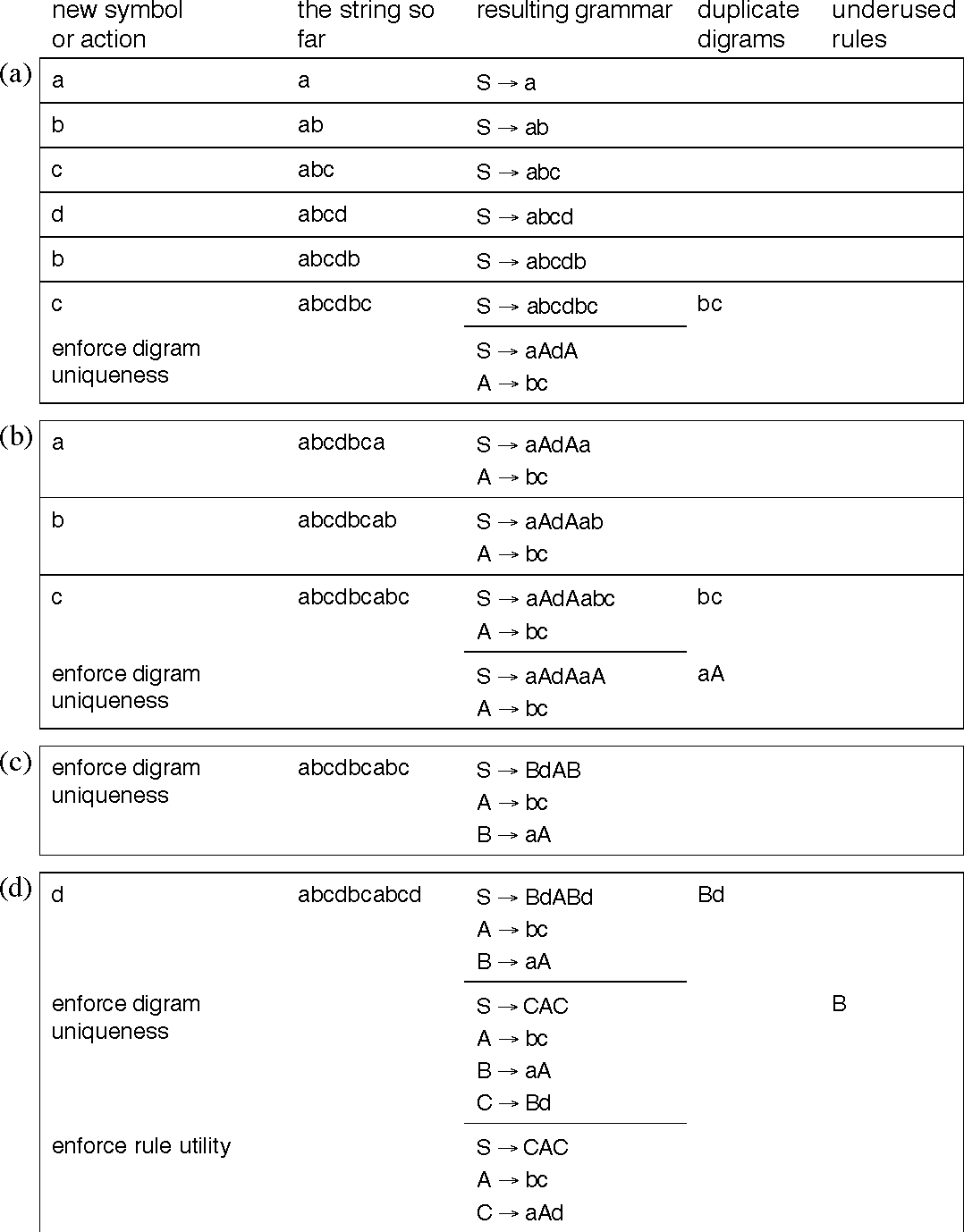
This is an algorthim that treats the dataset as a grammer, than seeks to replace the original data with the grammer required to develop the original dataset. This is a very cool systems, unfortunately from my understanding it is slower than the previous systems mentioned. However may offer greater compression ratios.
Machine Learning:
This is a bit extra and I have not personally worked with this, however I have heard about this from this video (HackerPoet).
Most Important Tidbits:
- Lossless compression is limited to a 2 to 1 compression
- Machine learning compression however is not limited
- Compression does not work for all datasets and in certain cases expands it